Every underwriter who works with credit reports has a set of decisions they make on every deal. Which accounts enter revolving utilization. Which enter DTI. Why a HELOC is revolving but excluded from utilization. Why Kikoff is not real debt. These decisions live in Excel formulas, in muscle memory, in tribal knowledge that gets re-derived from scratch on every file.
The question was whether you could make those decisions once, encode them in a typed model, and have the spreadsheet write itself with full provenance. Account type. Collateral. Status. Liability. The dimensions that determine how any tradeline enters any calculation. Map a tradeline through those dimensions and every downstream number follows from it.
Every credit report contains the same core data: a borrower, their FICO 8 scores, tradeline accounts, and hard inquiries. A tri-merge pulls from all three bureaus and packs the results into a single document. Below is a tri-merge from MyScoreIQ.
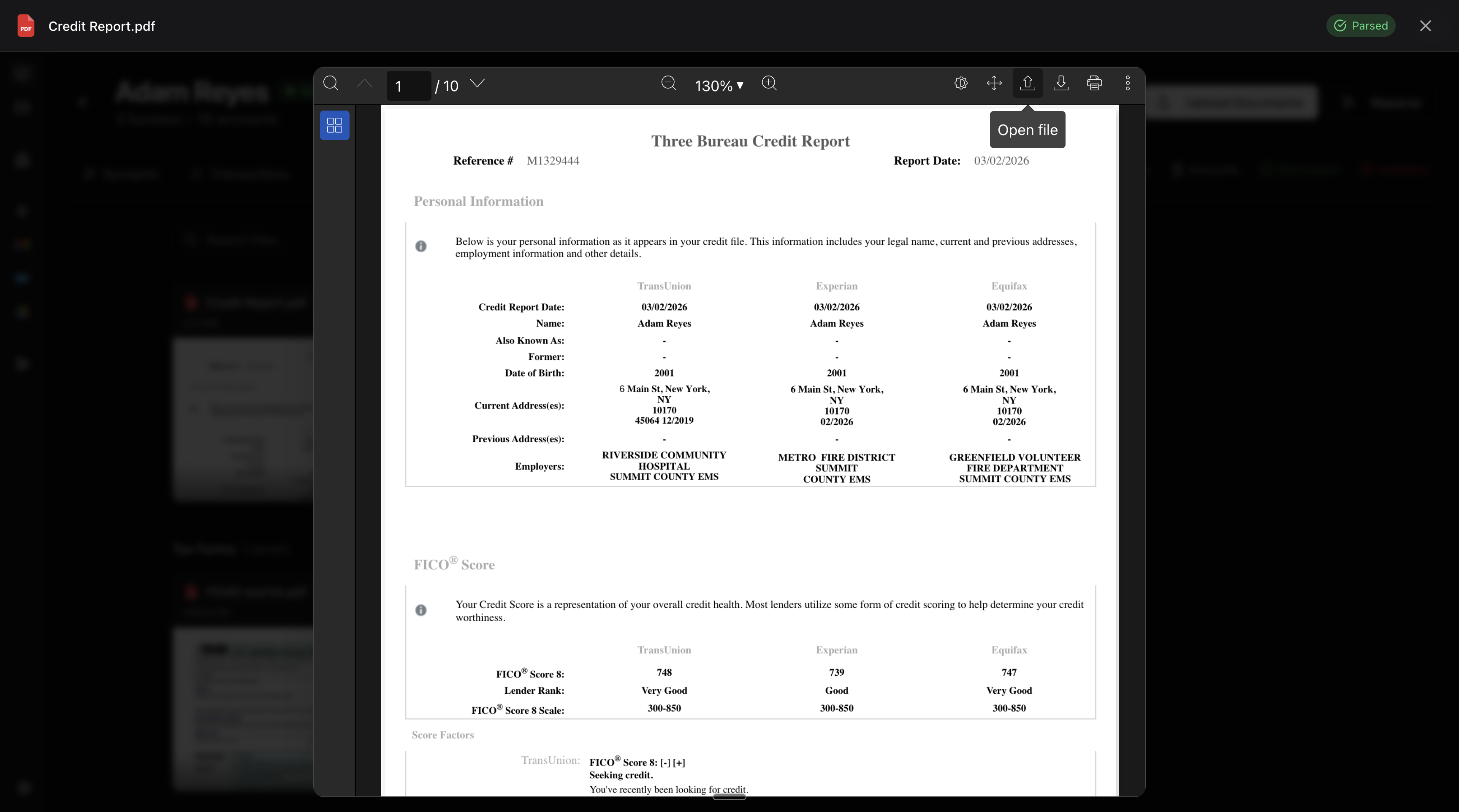
The format is never consistent. LexisNexis lays three bureaus in side-by-side columns. A single-bureau Experian pull is one linear document. A JSON import from a reseller gives you the same fields under different names in different nesting. The data underneath is always the same. The layouts never are.
The output
Pathway parses the credit report and generates a spreadsheet from it. One tab per bureau. FICO 8 scores across all three bureaus at the top, then summary blocks for revolving utilization, DTI, and derogatory history, then every tradeline as a classified row the underwriter can edit. The template is customizable and exports to Excel or Google Sheets.
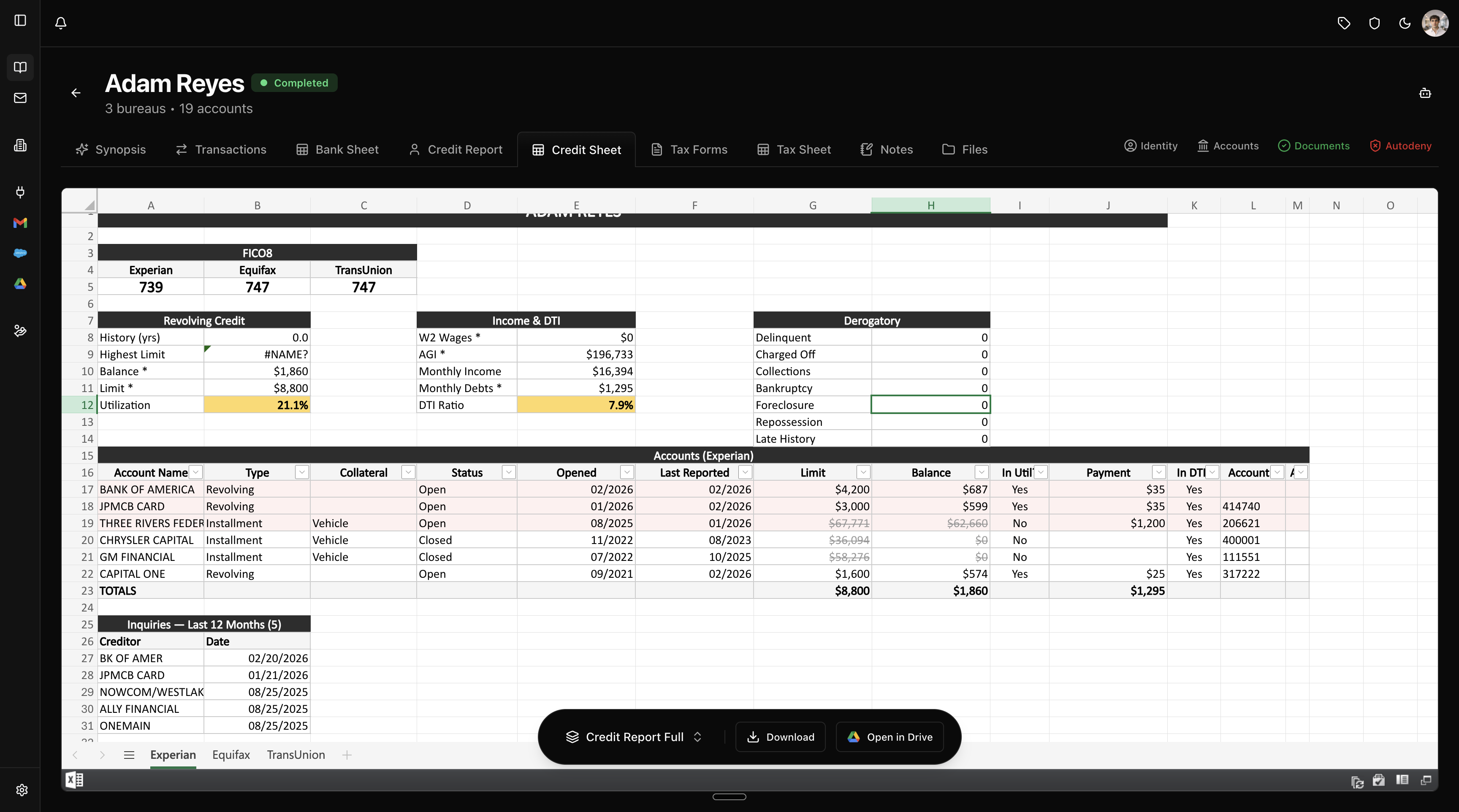
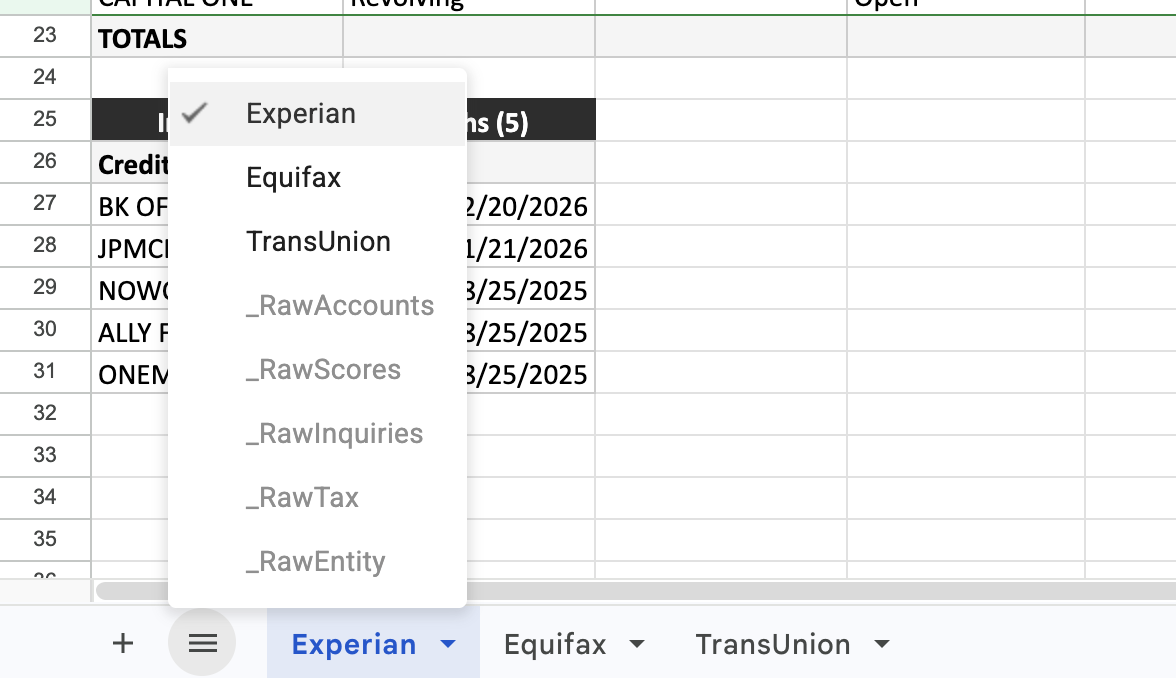
Each bureau gets its own tab. The underwriter can jump between Experian, Equifax, and TransUnion and reconcile tradelines across bureaus trivially. Raw data lives in hidden backing sheets that the presentation layer references with formulas.
Every account row has two toggle columns: “In Util?” and “In DTI?”. These control whether the account contributes to the revolving utilization and debt-to-income calculations in the summary. Mortgages default to excluded from utilization. Authorized user and credit builder accounts default to excluded from both. The underwriter can flip any toggle with a dropdown. The totals are SUMIF formulas against those columns, so every number traces back to exactly which accounts contribute.
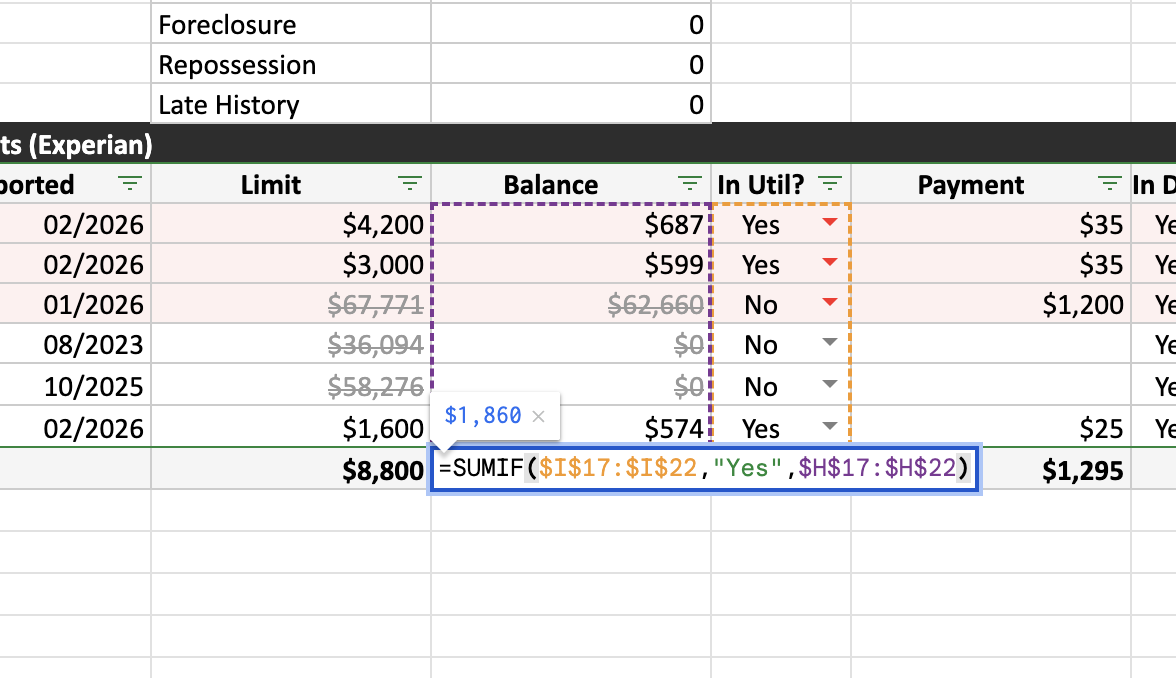
Change a toggle from Yes to No and the balance drops out of the utilization total. The summary and DTI follow. Every number has lineage back to the accounts that feed it.
How the classifications work
Account type
When the summary shows 4.7% revolving utilization, that number comes from dividing the total revolving balance ($2,896) by the total revolving limit ($61,900). Installment accounts, mortgages, and charge accounts are excluded from that calculation because utilization only applies to revolving credit. The parser has to know which accounts are revolving to compute this correctly.
REVOLVING # credit cards, lines of credit
INSTALLMENT # fixed payment loans
MORTGAGE # real estate
CHARGE # pay-in-full monthlyCollateral
Two installment loans with the same $500 monthly payment could be an auto loan and an unsecured personal loan. The collateral classification lets screening rules treat them differently because a secured auto loan and an unsecured personal loan represent different levels of borrower risk at the same payment amount.
VEHICLE # auto loans
REAL_ESTATE # mortgages, HELOCs
EDUCATION # student loans
UNSECURED # personal loans
CASH_DEPOSIT # secured credit cardsStatus and delinquency
The derogatory counts in the summary (delinquent, charged off, collections, bankruptcy, foreclosure, repossession) all come from two fields: account_status and worst_delinquency_days. Status alone does not distinguish between a paid-in-full account and a charged-off account that was closed after write-off. The worst_delinquency_days field (30, 60, 90, 120, 150, 180) captures the full payment history in a single number.
Authorized users and credit builders
Two boolean flags handle accounts that are not real obligations. is_authorized_user marks accounts where the borrower has access to someone else's credit line but is not legally responsible. is_self_reported marks credit builder products like Kikoff, SELF Financial, and Experian Boost. These flags control the default toggle state in the spreadsheet. An authorized user account on a $8,000 Amazon card and a $25 Kikoff credit builder both default to excluded from utilization and DTI unless the underwriter explicitly opts them in.
What sits between the PDF and the spreadsheet
The parser reads the document, extracts every account, classifies it, and writes the result into a typed object we call CRMeta. The spreadsheet template reads from this object, not from the PDF directly.
CRMeta
├── primary_entity
│ ├── full_name
│ ├── addresses[]
│ ├── date_of_birth
│ ├── has_fraud_alert
│ └── has_security_freeze
│
└── credit_report_body[] # one or more bureaus
├── credit_bureau
│ ├── name # experian | equifax | transunion
│ └── inquiries[]
├── fico_score # FICO 8
└── underwritten_accounts[]
├── account_name
├── account_type
├── collateral_type
├── account_status
├── worst_delinquency_days
├── is_authorized_user
├── is_self_reported
├── credit_limit
├── recent_balance
├── monthly_payment
└── datesSingle-bureau produces one entry in credit_report_body. Tri-merge produces three. That separation between the parse and the template is why you can customize the spreadsheet without re-parsing, and why every input format produces identical output.
I built the first version of this model with Vlad Rusev, a credit underwriter at Preferred Funding Group who can see a thousand deals on a heavy day. Vlad had been prompting LLMs, building agentic pipelines, trying every automation stack he could find to get credit analysis to hold together at that volume. We sat down and traced his Excel formulas backward until each one terminated at a tradeline, then encoded the decisions those formulas represented into the typed model above. The classifications, the toggle defaults, the collateral distinctions — all of it came from watching how an experienced underwriter actually reads a credit report and making those judgments persistent.
Since then, underwriting teams across the platform have run thousands of reports through the parser. Every edge case they surfaced sharpened the model. Today it handles hundreds of credit reports a day in production across every format we have seen. Any credit report in, one CRMeta out, one spreadsheet generated, ready for the read.