Pathway API
Automate document processing and embed Pathway analytics anywhere
Authentication
1. Generate API Token
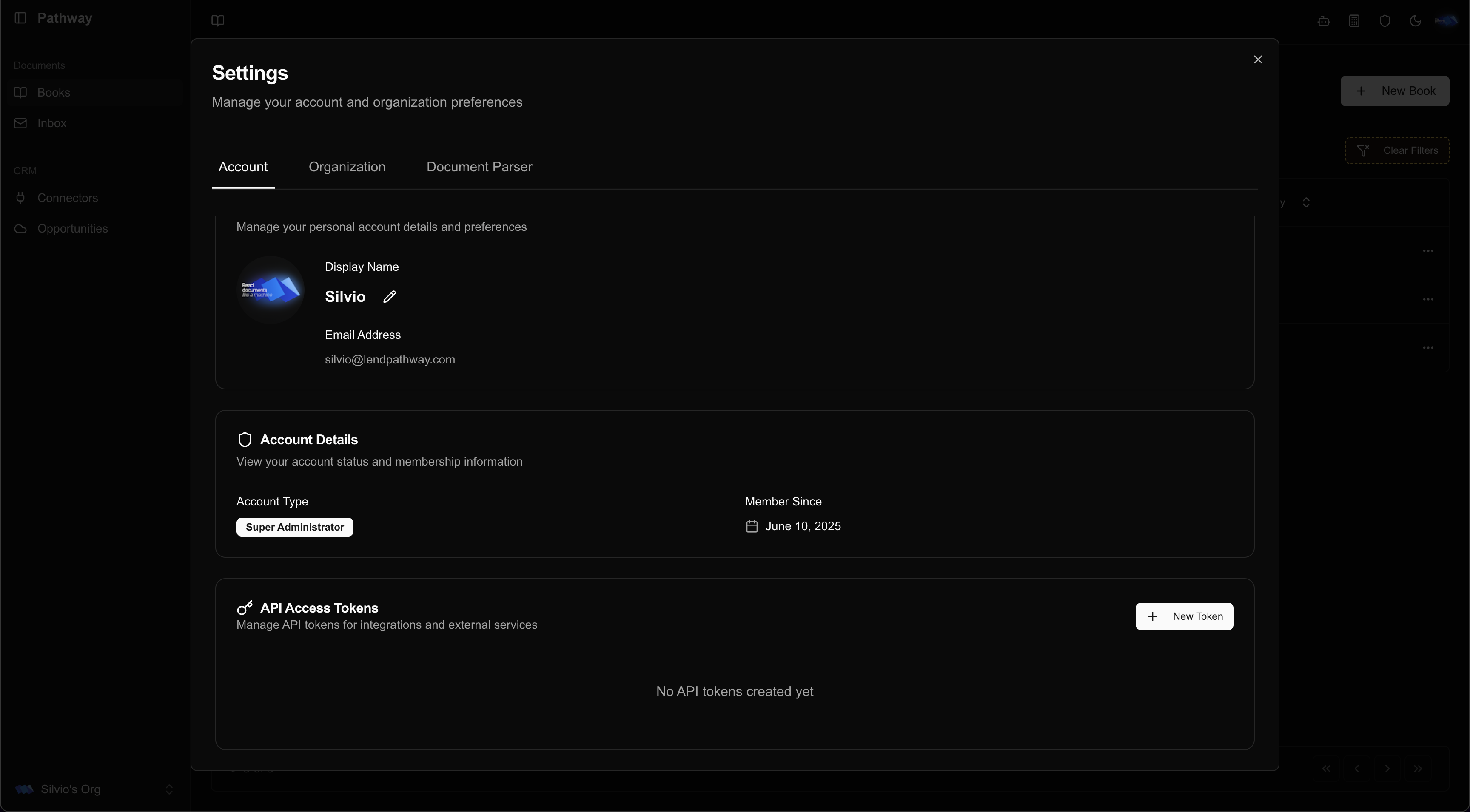
Settings → Account → New Token
2. Give it a name
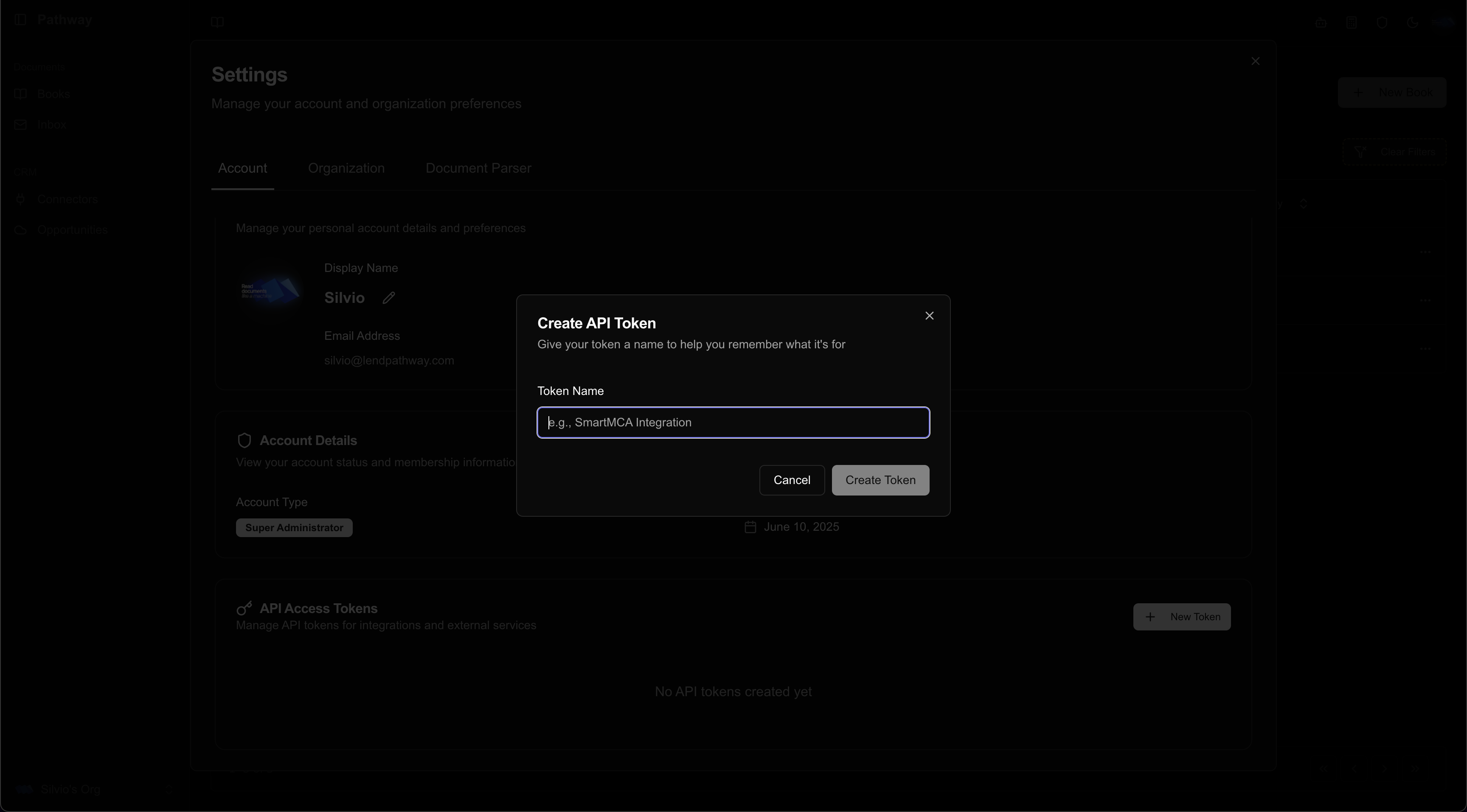
Use a descriptive name
3. Copy token
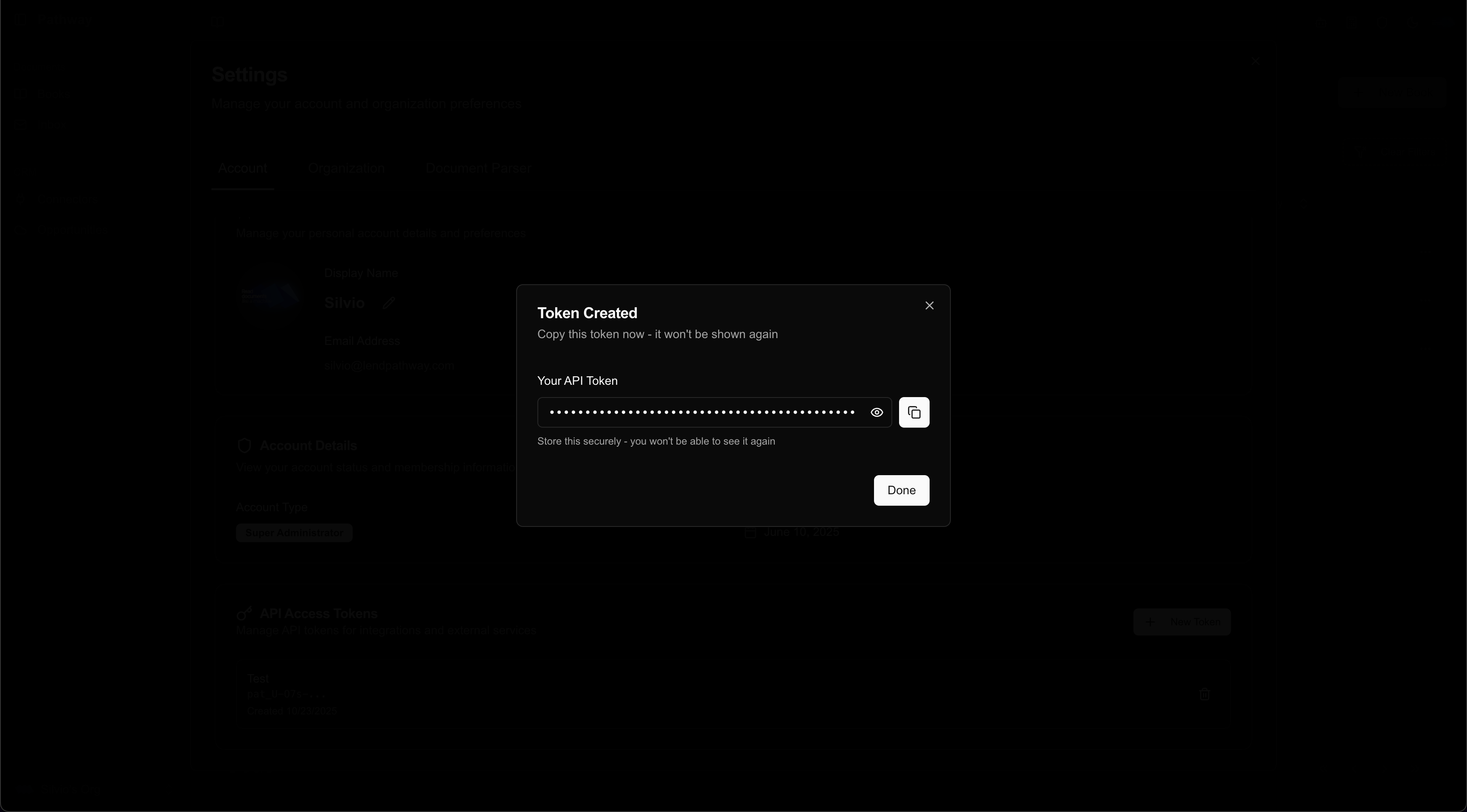
You will not be able to see this token again
Endpoints
Snippets
Test authentication, then submit and embed financial documents.
1. Verify Your Token
Confirms your API token works and shows your organization.
import requestsAPI_BASE_URL = "https://api.lendpathway.com/api"TOKEN = "pat_your_token_here" # Replace with your actual PAT tokenheaders = {"Authorization": f"Bearer {TOKEN}"}r = requests.get(f"{API_BASE_URL}/auth/me", headers=headers)if r.ok:print(f"Authentication successful: {r.json()['org_name']}")else:print(f"Authentication failed: {r.status_code} - {r.text}")
{
"org_id": "c4f9dda9-7875-4115-961f-0ac4b9630526",
"org_name": "Your Company",
"user_id": "fa576914-9590-40af-bbb8-c3af6f500859",
"user_name": "John Doe"
}{
"detail": "Invalid or revoked access token"
}2a. Submit with Webhook
Fire-and-forget: submit files, get notified via webhook when processing completes.
import requestsAPI_BASE_URL = "https://api.lendpathway.com/api"TOKEN = "pat_your_token_here" # Replace with your actual PAT tokenheaders = {"Authorization": f"Bearer {TOKEN}"}# Submit book with webhook notificationwith open("path/to/your/statement.pdf", "rb") as f:r = requests.post(f"{API_BASE_URL}/submit-book",headers=headers,files={"files": ("statement.pdf", f, "application/pdf")},data={"book_name": "Q3 Statements","description": "Bank statements for Q3","webhook_url": "https://your-server.com/webhook"})if r.ok:result = r.json()print(f"Book submitted: {result['book_id']}")print(f"Status: {result['status']}")print(f"Check your webhook endpoint for completion notification")else:print(f"Failed: {r.status_code} - {r.text}")
{
"book_id": "99cc93e6-1f3f-42b1-9fe4-ba5a95be9c78",
"status": "processing",
"message": "Processing started"
}{
"book_id": "99cc93e6-1f3f-42b1-9fe4-ba5a95be9c78",
"status": "success",
"book_url": "https://app.lendpathway.com/books/99cc93e6-1f3f-42b1-9fe4-ba5a95be9c78"
}2b. Submit with Polling (Full Flow)
Complete flow: submit, poll for completion, generate embed URL when ready.
import requestsimport timeAPI_BASE_URL = "https://api.lendpathway.com/api"APP_BASE_URL = "https://app.lendpathway.com"TOKEN = "pat_your_token_here" # Replace with your actual PAT tokenheaders = {"Authorization": f"Bearer {TOKEN}"}# 1. Submit book with files (one-shot upload + parse)with open("path/to/your/statement.pdf", "rb") as f:r = requests.post(f"{API_BASE_URL}/submit-book",headers=headers,files={"files": ("statement.pdf", f, "application/pdf")},data={"book_name": "Q3 Statements","description": "Bank statements for Q3","webhook_url": "https://your-server.com/webhook" # Optional: replace with your webhook URL})if not r.ok:print(f"Submission failed: {r.status_code} - {r.text}")exit(1)book_id = r.json()["book_id"]print(f"Book submitted: {book_id}. Processing in background.")print(f"If webhook_url was provided, check your endpoint for updates.")# 2. Poll for completion (if not using webhook)print("Polling for completion (if no webhook configured)...")while True:r = requests.get(f"{API_BASE_URL}/books/{book_id}", headers=headers)if not r.ok:print(f"Error polling status: {r.status_code} - {r.text}")exit(1)book_status = r.json().get("parse_status", {}).get("status", "unknown")print(f" Current status: {book_status}")if book_status in ["success", "error"]:print(f"Processing finished with status: {book_status}")breaktime.sleep(5) # Wait 5 seconds before polling again# 3. Generate embed token for iframeif book_status == "success":r = requests.post(f"{API_BASE_URL}/embed/token",headers=headers,json={"book_id": book_id})if r.ok:embed_token = r.json()["embed_token"]print(f"Embed URL: {APP_BASE_URL}/embed/{embed_token}")else:print(f"Failed to generate embed token: {r.status_code} - {r.text}")
{
"embed_token": "emb_VWUCi3ml0L05CSkgZNBli4hKs8ObZrzaO9XGRUySJ8A",
"book_id": "99cc93e6-1f3f-42b1-9fe4-ba5a95be9c78",
"expires_at": "2025-10-25T15:37:46Z"
}3. Explore Books & Analytics
List all books and access parsed financial data including accounts, transactions, and analytics.
# List all booksr = requests.get(f"{API_BASE_URL}/books/", headers=headers)books = r.json()print(f"Found {len(books)} books")# Get analytics for a specific bookbook_id = books[0]["id"]r = requests.get(f"{API_BASE_URL}/books/{book_id}/analytics", headers=headers)analytics = r.json()# Show key metricsprint(f"Total Deposits: $${analytics['total_deposits']:,.2f}")print(f"Total Withdrawals: $${analytics['total_withdrawals']:,.2f}")print(f"True Revenue: $${analytics['true_revenue']:,.2f}")print(f"Average Daily Balance: $${analytics['average_daily_balance']:,.2f}")print(f"Accounts: ${len(analytics['merged_accounts'])}")
{
"total_deposits": 125000.50,
"total_withdrawals": 98000.25,
"true_revenue": 87000.00,
"average_daily_balance": 15250.75,
"positions": [
{
"position_id": "pos-uuid",
"name": "MCA Position 1",
"loan_type": "merchant_cash_advance",
"total_disbursements": 50000.00,
"total_payments": 12500.00
}
],
"merged_accounts": {
"123456789": {
"account_name": "Business Checking",
"transactions": [
{
"transaction_id": 1,
"transaction_date": "2025-07-02",
"description": "Payment received",
"amount": 1200.50,
"transaction_type": "credit",
"tag": ["payment_processor", "true_revenue"]
}
]
}
}
}4. Analyze Transactions
The parsed data is yours to query however you need. Here's one example: aggregating credits by weekday.
from datetime import datetimefrom collections import defaultdict# Get analytics with all computed metricsr = requests.get(f"{API_BASE_URL}/books/{book_id}/analytics", headers=headers)r.raise_for_status()analytics = r.json()# Aggregate credits by weekdayweekdays = ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"]credits_by_day = defaultdict(lambda: {"total": 0.0, "count": 0})# Iterate through all accounts and transactionsfor account in analytics["merged_accounts"].values():for tx in account["transactions"]:if tx["transaction_type"] == "credit":day = weekdays[datetime.strptime(tx["transaction_date"], "%Y-%m-%d").weekday()]credits_by_day[day]["total"] += tx["amount"]credits_by_day[day]["count"] += 1# Display resultsfor day in weekdays:if day in credits_by_day:data = credits_by_day[day]print(f"${day}: $${data['total']:,.2f} (${data['count']} transactions)")
Monday: $12,450.00 (8 transactions) Tuesday: $9,320.50 (6 transactions) Wednesday: $15,780.25 (11 transactions) Thursday: $8,940.75 (5 transactions) Friday: $11,235.00 (7 transactions) Saturday: $3,210.50 (2 transactions) Sunday: $1,890.00 (1 transactions)
Full Reference
These examples show bank statement parsing. We also support credit reports, AR aging reports, and more document types. See the full API reference for complete endpoints, schemas, and response formats.
Open API Reference